

Descargar el ejemplo xls
Usualmente, en análisis instrumental se puede conocer la concentración de un determinado mesurando de manera indirecta; es decir, midiendo una propiedad física que sea proporcional a la concentración de este. Entonces, lo que se hace es establecer una relación directa entre las señales y las concentraciones conocidas de los patrones que originan dichas señales, y se procura cubrir el rango completo de trabajo para facilitar el cálculo en subsiguientes análisis. Lo que resta es establecer un modelo matemático que permita interpolar los valores de las señales de muestras desconocidas y con ello calcular su concentración. Generalmente se usa una regresión de tipo lineal por su simplicidad matemática (al menos cuando el método lo permite),
Usualmente, en análisis instrumental se puede conocer la concentración de un determinado mesurando de manera indirecta; es decir, midiendo una propiedad física que sea proporcional a la concentración de este. Entonces, lo que se hace es establecer una relación directa entre las señales y las concentraciones conocidas de los patrones que originan dichas señales, y se procura cubrir el rango completo de trabajo para facilitar el cálculo en subsiguientes análisis. Lo que resta es establecer un modelo matemático que permita interpolar los valores de las señales de muestras desconocidas y con ello calcular su concentración. Generalmente se usa una regresión de tipo lineal por su simplicidad matemática (al menos cuando el método lo permite),

Donde (a) es la intersección con el eje (y) y (b) es la pendiente de la curva.
En esta nota se pretende calcular la ecuación de una curva de calibrado con algunos de sus atributos. Para tal fin, se cuenta con una serie de datos de concentración teórica de patrones y sus respectivas señales.

Lo que sigue es generar la gráfica de calibrado accediendo a la pestaña insertar, opción gráficos de dispersión.

Dentro de las opciones del gráfico encontramos agregar línea de tendencia (al hacer click derecho sobre los puntos del gráfico). Seleccionamos lineal, escogemos presentar ecuación en el gráfico y presentar el valor de R cuadrado (coeficiente de determinación) en el gráfico.

A continuación lo que hacemos es calcular la estadística básica de la curva, mediante la función ESTIMACIÓN.LINEAL() de manera matricial. Pronto estaré escribiendo una nota acerca de esta forma de trabajar con MS Excel.
=ESTIMACIÓN.LINEAL(Conocido_y;Conocido_x;Constante;Estadística)
Donde:
conocido y: es una referencia a un rango que contiene valores dependientes.
conocido x: es una referencia a un rango que contiene valores independientes.
constante: es un valor lógico opcional, si es VERDADERO u omitido la función calcula el valor de la pendiente, si es FALSO, la pendiente pasara por cero.
estadística: es un valor lógico opcional, indica si se calcula o no las estadísticas de regresión adicionales.
Entonces, seleccionamos una matriz de cinco filas por dos columnas y formulamos lo siguiente:
={ESTIMACION.LINEAL(D4:D21;C4:C21;VERDADERO;VERDADERO)}

Y lo que obtenemos es:

A partir de la desviación estándar residual y la pendiente se puede calcular la desviación estándar de la curva Sx0.


El resultado es:

También se puede calcular el coeficiente de variación del método (%CV) dividiendo Sx0 entre el promedio de las concentraciones.

El resultado es:

Para obtener el coeficiente de correlación (r) se puede obtener la raíz del coeficiente de determinación (r2) o se puede usar la función COEF.DE.CORREL (matriz1; matriz2).
Donde:
matriz1, matriz2; son rangos de celdas de igual número de filas y columnas de los cuales se busca obtener el coeficiente de correlación, es decir, el grado de relación entre los rangos de valores.

Se calcula el (r) de las dos formas y obtenemos el mismo valor.
En torno a este tema se pretende aclarar la diferencia entre estos dos coeficientes (r y r2).
El coeficiente de correlación (r) asume valores adimensionales entre -1 y +1 e indica que tanta relación hay entre las variables; entre más cerca este de los anteriores valores, mayor será el grado de relación.
El coeficiente de determinación (r2) asume valores adimensionales entre 0 y +1 e indica el porcentaje de variabilidad de la variable dependiente que se puede explicar por la variabilidad de la variable independiente.
Ej. Si se tiene un r² = 0,99999 a partir de la correlación entre patrones de Calcio y volúmenes de EDTA, se podría afirmar que el 99,999% de la variabilidad de los volúmenes de EDTA se pueden explicar por la variabilidad de concentración de los patrones de calcio.
Ahora evaluaremos si el ajuste lineal es válido, para ello haremos uso del Test F de Linealidad.
Este Test se basa en descomponer la varianza existente entre las señales experimentales y los valores predichos en dos aportes. Uno de ellos es el error experimental. Para tener una estimación del error experimental en la medición de las señales, debemos medir “i” replicados de cada patrón, por lo que para cada punto x habrá varios valores de señal (yi).

Donde n es el número total de mediciones, k es el número total de patrones, i son las repeticiones de cada patrón y los yij son las señales de todos los experimentos.
Para estimar el posible error debido a una falla de ajuste debida a la elección de un modelo incorrecto, calculamos la media de los cuadrados debida a la “falta de ajuste” (MSLOF, Mean Squares Lack of Fit):

Esto mide la diferencia media entre la media de las réplicas de cada patrón y su correspondiente valor estimado por la regresión. Cabe esperar que si el modelo lineal es correcto, las varianzas MSLOF y MSPE serán comparables. Si MSLOF es mayor que MSPE el ajuste no es correcto y hay que utilizar otro modelo o reducir el ámbito de concentraciones en el cuál se hace el calibrado.

Si Fcal < Fk-2,n-k,a (obtenido de tablas) se acepta que existe buen ajuste al modelo lineal.
Después de la teoría, vamos a practicar con nuestros datos..
Para calcular el error experimental es preciso conocer el número de datos, el número de de niveles de concentración además de dos columnas auxiliares; una que calcule el promedio de señales por nivel y otra que calcule el error experimental.
Primero, número de datos:
Para calcular el error experimental es preciso conocer el número de datos, el número de de niveles de concentración además de dos columnas auxiliares; una que calcule el promedio de señales por nivel y otra que calcule el error experimental.
Primero, número de datos:

Después, el número de niveles. Este resulta de dividir el número de datos entre el número de replicas por nivel, que dicho sea de paso, se define al inicio del proceso.


Posteriormente se calcula el promedio de señales por nivel de concentración.

Aparece la columna que calcula el error experimental. Resulta de la resta entre la señal y el promedio de señal por nivel elevada al cuadrado.

La varianza debida al error experimental surge de dividir la suma de la columna "Error Exp" entre el número de datos menos el número de niveles.

El resultado:

Para calcular el error debido a la regresión, necesitaremos una columna axiliar que denominaremos "Error Regresión". en esta se hará uso de la función TENDENCIA para calcular la señal esperada, a esta se le restará el promedio de señal por nivel, y finalmente se elevará al cuadrado.
Aquí una breve explicación de la función.
La función TENDENCIA predice valores para variables dada una relación entre dos grupos de valores.
conocido y: es una referencia a un rango que contiene valores dependientes.
conocido x: es una referencia a un rango que contiene valores independientes.
nueva matriz x: es una referencia a un rango el cual posee valores a pronosticar.
constante: es un valor lógico opcional, si es VERDADERO u omitido la función calcula el valor del término independiente, si es FALSO el término independiente es cero.

La varianza debido a la regresión surge de la suma de la columna "Error Regresión" dividida entre el número de niveles de concentración menos dos.


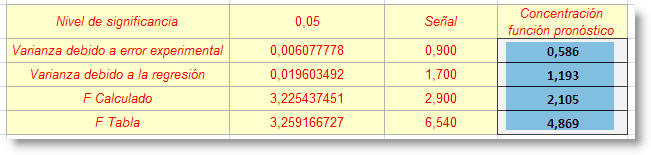
A partir de la división de la varianza debido a la regresión entre la varianza debido al error experimental, surge el F calculado.

Finalmente calculamos el F de Tabla con la función:
La función DISTR.F.INV devuelve el valor que de una probabilidad sigue una distribución F de Snedecor.
probabilidad: valor entre 0 y 1 que indica la probabilidad.
grados de libertad1: es el número de datos (menos uno) utilizados en la variable A.
grados de libertad2: es el número de datos (menos uno) utilizados en la variable B.
En nuestro caso, la probabilidad corresponde a 0,05 (nivel de significancia).
Grados de libertad 1 corresponde al número de niveles menos dos.
Grados de libertad 2 corresponde al número de datos menos el número de niveles.

El resultado....

Se concluye que existe un buen ajuste de los datos al modelo lineal, dado que Fcalculado < F Tabla
Para concluir esta prolongada nota procuraremos predecir valores de concentración a partir de señales con al función PRONOSTICO.
La función PRONOSTICO predice un valor para una variable, dada una relación conocida de la misma (del tipo y = a + bx).
x: es el valor que se quiere pronosticar.
conocido y: es una referencia a un rango que contiene valores dependientes conocidos.
conocido x: es una referencia a un rango que contiene valores independientes conocidos.
La señal será el valor que se quiere pronosticar.
Conocido de y es el rango de las concentraciones.
Conocido de x es el rango de señales.


Chingon!
ResponderBorrarbuenos días, hay alguna posibilidad de descargar una hoja de calculo de lo que estas explicando
ResponderBorrarBuenos días, me pueden explicar como obtener la tabla con los resultados de la estimación lineal, ya que cuando hago este cálculo solo me aparece como resultado el valor de la pendiente en una celda, pero no la tabla completa con todos los resultados como se ve en el ejemplo.
ResponderBorrarGracias
Hola.Gracias por comentar en nuestro sitio.
ResponderBorrarAntes de formular, debes señalar una matriz de 5 filas por 2 columnas, y finalizar con los comandos:control+shift+enter.
Esto debería solucionar tu inquietud.
Buenas tardes:
BorrarSigo con el mismo problema al tratar de obtener la estimación lineal. Yo tengo Excel 2010 y cuando entro la matrix de 2 columnas y 21 filas que se corresponde con tres repeticiones de la curva de calibración de siete puntos, en lugar de obtener la tabla completa con todos los estadígrafos obtengo solamente la pendiente del gráfico en una sola celda. Me podrían ayudar por favor,
Gracias
Cordial saludo.
BorrarComo he visto dos pedidos de aclaración acerca de ¿cómo usar la función Estimación.Lineal?
He publicado un video acerca del tema: http://mbexcel.blogspot.com.co/2016/10/multiplicar-horas-y-minutos-por-enteros.html
Espero que sea de gran ayuda.
buen día, en varianza debido a la regresión en donde le restas 2, ¿Ese numero es constante, o cambia según los datos que manejes? De igual forma en DIST.F.INV
ResponderBorrarsaludos